Today, I’d like to walk you through my journey over the past month while working on a recent project. This is not a tutorial; it is a record of what failed, what surprised me, and what I learned the hard way.

Table of contents
Open Table of contents
- Why I Started This Project
- Catching Up on the Literature (And Realizing How Big This is)
- Choosing Wan-Vace (And Why 1.3B Was a Compromise)
- Data: The Most Time-Consuming Part Nobody Warns You About
- Prompt Engineering at Scale (A Hack, Not a Solution)
- Fine-Tuning: Where Everything Broke
- What Should I Do Now?
- Inference-Time Analysis: The Relative Win
- What I Learned
- If I Had More Time and Resources
- Codebase
- Stay Connected
Why I Started This Project
This project is part of my current semester module, Foundational Models.
Generative AI is an emerging field that is rapidly transforming the media industry. To some extent, most of us have already used AI to edit images or videos. Personally, I was curious to dive deeper into the field of controllable video generation and understand how these latest systems work.
Catching Up on the Literature (And Realizing How Big This is)
Personally, I was more inclined to work with state-of-the-art models and support the community, even if only through a small contribution. At that point, I realized I lacked proper awareness of the literature in this domain. So, I started by reading a survey paper on controllable video generation. It gave an in-depth overview of the field, from the early days of generative AI to the current state of the art. Reading about GANs again felt a bit nostalgic.
While going through the paper, I realized that controllable video generation is a very broad topic. It covers many different types of control adapters, such as text, reference images, identity, bounding boxes, pose, depth, style, voice, and more. I understood that controllable video generation is not a single problem; it can be approached in multiple ways, either using a single control signal or by combining several of them.
Many works in the literature show that using more than one controller often leads to better results. That pushed me to start looking for a model designed to handle multiple controls instead of just one.
Choosing Wan-Vace (And Why 1.3B Was a Compromise)
The core architecture used in generative AI has changed over time. Most of the existing literature is based on U-Net–style Stable Video Diffusion models, which felt a bit outdated to me. Diffusion Transformer (DiT)–based models, on the other hand, felt like the future.
When it came to model selection, Wan was a clear winner. It has open-sourced weights and one of the most advanced architectures available. Within the Wan model family, the model that aligned best with my goal of combining multiple controls was Vace. It includes a Video Conditioned Unit (VCU), which allows different modalities to be combined during video generation.
Vace comes in two sizes: 1.3B and 14B parameters. Due to resource constraints and the fact that this was a hands-on experiment, I chose the 1.3B model. My thinking was simple: if the idea worked at this scale, it would be worth investing in scaling it up later.
I tried generating a few videos using the provided pretrained weights. The results looked good, but they were not spatially consistent. What should I do next?
I thought that if I fine-tuned the model on dance videos, it might help generate dance sequences with better spatial consistency.
Data: The Most Time-Consuming Part Nobody Warns You About
I needed data. I looked at a few datasets, such as the TikTok video dataset, and the AIST++ dance video dataset. The AIST dance video dataset is massive, and for a hands-on project like this, I needed something smaller and more manageable. The simple dance dataset contains nearly 1,500 unique simple dances, each recorded from nine different camera angles to capture the dancer’s pose from all sides. I decided to go with the AIST++ dataset since it already provides 2D keypoints that I could potentially use directly.
I prepared a small script to download videos with randomly selected camera angles so the dataset would be more diverse and the model wouldn’t overfit to a single viewpoint, such as only the front-facing camera.
The videos were downscaled from 1080p at 59.99 FPS to 720p at 16 FPS and trimmed from the original 12 seconds to 5 seconds. This was necessary because the Wan-Vace model supports videos of up to 81 frames. I also extracted the initial frame from each processed video, as this frame is used by the model as the starting point to predict subsequent frames.
Then came the most important part: pose videos.
Initially, I assumed that the skeleton keypoints provided by AIST++ would work well with Wan-Vace. That assumption turned out to be wrong. Wan-Vace relies on DWPose-based keypoint extraction, which captures full-body joints, detailed facial expressions, and even individual finger movements—information that is not available in the AIST++ annotations. Even if those keypoints were available, they would still require manual remapping to match the pose representation expected by Wan-Vace.
Solution: I had to regenerate all pose videos from scratch using the DWPose script.
Prompt Engineering at Scale (A Hack, Not a Solution)
I went ahead and found in the Vace paper that the model relies heavily on the input prompt. Because of this, it was essential to develop a dynamic prompt for each sample.
If I kept a static prompt for every video, the model’s weights would eventually dominate and the prompt would have little to no effect during generation.
I found a hack. First, the AIST video filenames contain useful metadata such as the camera number and dance type. For example, gBR_sBM_c01_d04_mBR0_ch01.mp4 in which c01 refers to the first camera positioned in front, and gBR indicates breakdance. This metadata turned out to be quite helpful.
Second, I already had the extracted video clips and initial frames. Using full video clips to generate descriptions would have been very costly in terms of computation and processing time. Instead, I used the initial video frame to generate an image description and combined it with the metadata. This was enough to create a reasonably accurate and dynamic prompt for each sample. I used Florence-2-base and Qwen2.5-0.5B to generate the final prompts.
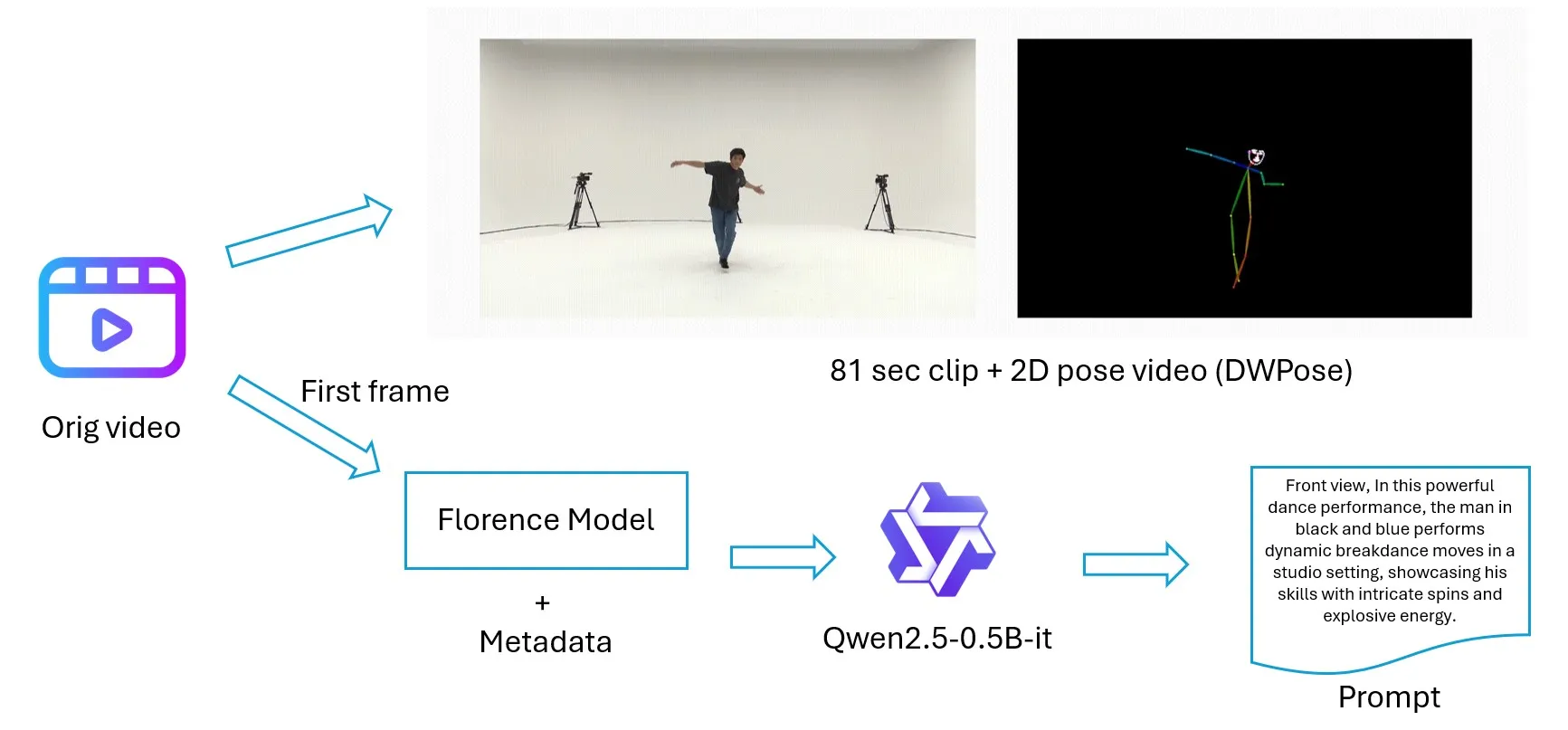
This method is not perfectly accurate for prompt generation, but given the trade-off between time, resources, and necessity, it was the best option for my situation.
Fine-Tuning: Where Everything Broke
Yayy, the data was finally ready, and I was very happy. I wanted to move from inference code to training code. I searched… searched… and kept searching. Of course, Vace does not provide any training code. That’s when I had a bit of a mental breakdown. What should I do now?
Fortunately, the AI community is very supportive. DiffSynth-Studio came to the rescue, and suddenly all the data preparation didn’t feel like a waste anymore.
I used vast.ai for fine-tuning (a quick warning: the technical support team can directly access your instance and see what’s inside, which I wasn’t expecting, so be aware of that. Still, it was the cheapest option I could find).
The setup had nearly 32 million trainable parameters with a LoRA rank of 32. It took almost three days to fine-tune a single epoch on an RTX 6000 Ada. I was excited to see the final results. However, when I tested the last checkpoint, I realized the model was no longer following the reference image and was instead generating videos that looked very similar to the AIST dance videos.
It turned out that LoRA didn’t just learn motion. It also learned identity and spatial bias, which is visible in the generated outputs below.

What Should I Do Now?
I did what you’re probably thinking: ChatGPT, Gemini, and DeepSeek.
I wasn’t sure which direction to go next. One option was to use an identity-based adapter in addition to the skeleton control, specifically to focus on facial reconstruction and preserve identity (similar to Concat-ID). Another option was to take the generated video and apply post-processing techniques, such as a GAN-based face reconstruction model, to fix the final output. Overall, most of these suggestions were expensive in terms of both time and computational resources.
One idea that really caught my attention was modifying the LoRA modules so that they would primarily learn temporal features, for example by targeting self-attention blocks. I took a risk and fine-tuned LoRA again for 600 steps. Unfortunately, it was also a disaster. The model still learned the skeleton structure and spatial bias.
At that point, I was left with only one option: could I get the most out of inference time?
Inference-Time Analysis: The Relative Win
Which parameter tuning would give me better results? I focused on a few key parameters and analyzed how each one affected the final output.
1. Guidance Scale
The reference image is used to condition the diffusion model’s noise prediction. Increasing the guidance scale pushes the sampling process closer to the reference image distribution. What I observed was simple but important: the stronger the guidance, the more the generated video resembles the input image. However, too much guidance sometimes reduced motion diversity.
When comparing the pretrained and LoRA models side by side, the difference is quite clear. In the pretrained model, changes in the overall background are more noticeable as the guidance increases. In the LoRA-fine-tuned model, the identity bias is much stronger and visible in the pants color that it follows from the reference image.


2. Sample Steps
Sample steps control how many denoising iterations the model performs during inference. In general, more steps lead to higher-quality videos with smoother motion and fewer artifacts. However, the improvement after a certain point was marginal, while inference time increased significantly. From my experiments, increasing steps helped refine motion consistency, but it did not fix identity drift on its own.


3. Prompt Engineering
Prompt engineering turned out to be one of the most impactful factors. I generated a detailed description of the reference image and then created multiple prompt variants, each focusing on a different aspect such as identity, lighting and quality, and cinematic style. Carefully phrased prompts helped guide the model toward better balance between identity and motion, especially when combined with higher guidance scales.

Here are the prompts used to generate videos for both models:
-
Detailed Default: “A high-quality video of a young adult man with medium brown skin, an oval face, and dark brown almond-shaped eyes. He has thick black wavy hair, short on the sides, and wears modern thin metal-framed rounded rectangular glasses. He is dressed in a plain black crew-neck t-shirt, slim-fit dark washed jeans, and light beige sneakers. He performs a smooth, natural dance following the skeleton pose exactly in a clean, minimalist indoor setting with soft lighting. 4k, photorealistic, consistent character.”
-
Lighting and Quality-Focused: “Cinematic footage of a man with medium brown skin and wavy black hair, wearing metal-framed glasses and a casual black t-shirt with dark jeans. The lighting is professional studio quality, casting soft shadows that define his jawline and approachable presence. He is dancing with fluid, grounded movements. The camera remains steady, capturing the fine textures of his denim jeans and beige sneakers. Extremely detailed, 8k, filmic look.”
-
Identity-Focused: “Detailed portrait-style video of a man with almond-shaped eyes, neatly shaped eyebrows, and a thin mustache with light stubble. He wears rounded rectangular metal glasses. The subject is wearing a black t-shirt and dark slim jeans, performing a modern dance. Focus on maintaining the exact facial proportions and short wavy hairstyle throughout the motion. The background is a stable, modern gray room. High temporal consistency, sharp focus on the face.”
4. LoRA Alpha
For the fine-tuned model, LoRA alpha controls how much influence the LoRA weights have during inference. Lower values reduced the dominance of the fine-tuned motion patterns, while higher values made the output look more like the training data. Tuning this parameter was crucial to finding a balance where the model could follow the pose while still respecting the reference image.
As you can see, higher values of alpha generate video backgrounds that look closer to the dataset samples.

What I Learned
I think I rushed into the project. My curiosity to train big models and make a big impact ended up pulling me away from the right direction I should have taken. These are the lessons I learned throughout the journey:
- Fine-tuning video diffusion is not neutral
- Pose control does not mean identity control
- LoRA is powerful but blunt
- Inference-time tuning can rescue bad training
- Resource constraints shape research more than theory
If I Had More Time and Resources
While writing this, if I were to start this project again, I would approach the problem very differently. I feel like I didn’t really test the true power of Wan-Vace as a foundational model. It’s definitely better than what I initially expected. In hindsight, some of the things I did at the beginning might not have been necessary at all.
-
If my goal was to generate dance videos of myself, then I should have collected data of myself in the first place. In that case, LoRA might have worked much better.
-
Using Wan-Vace as a base model and working more deeply on the conditioning unit rather than fine-tuning the entire model could open up interesting directions for further research.
Codebase
The code is available in the skeleton2Video repository.
Stay Connected
If you’d like to connect or discuss, feel free to reach out.